PREFACE
Firstly, much the data and work in the post below was created for SpatialJam by Robert Harrison, who has generously volunteered his time and expertise on a number of projects over the past year or so, providing outstanding insight and a depth of skill way beyond my own. I did help with some of the words and colourful pictures though…
Robert is currently working as a Data Scientist with a number of years experience delivering analytical outputs across a range of industries. However, one of his big passions in life is following and getting involved with all things sport, and in particular, basketball. Finding a way to use his analytical skills to add value in a sporting context is something he’s wanted to do for a long time, and is hoping to continue to develop new and insightful pieces of analysis to share with the wider basketball community.
Thanks Robert for your amazing contribution - hopefully the first of many!
ANALYSIS OVERVIEW
This is an analysis of the NBL player types based on box score statistics.
The project takes all boxscore statistics from the past four NBL seasons (2015-16, 2016-17, 2017-18 and 2018-19) and attempts to create an understanding of player types based on an individual’s statistics and tendencies as opposed to simply looking at their 1 to 5 positions on the court. The modern game of basketball has significantly altered how we should assess and categorise players. It is becoming increasingly difficult to group players into the traditional 5 categories (Point Guard, Shooting Guard, Small Forward, Power Forward, Centre) - these groups have become far more fluid, with players’ skill-sets often fitting the description of multiple traditional positions.
Because the NBL has a very short (28 game) season relative to other international leagues - most notably the NBA, data analysis is often volatile due to noisy data created from small sample sizes. The aim here is to use the results of this analysis to understand more about player tendencies and create groupings or clusters based on these similarities. By grouping players into clusters rather than viewing them as individual players we greatly increase the sample size available to us, although this does come at the cost of data granularity. Through this clustering we may be able to get a better understanding of which lineup combinations are most appropriate in particular circumstances, such as countering an opponent, or creating the best chance of an open three point attempt.
PLAYER LEVEL DATA SAMPLE
PREPARING DATA FOR PRINCIPAL COMPONENT ANALYSIS
Firstly, the player dataset has been restricted to those players who have played on average at least 5 minutes per game and have played more than 10 games. All other players will fit into an ‘other’ cluster for future lineup analysis that will follow this initial work.
The data has also been scaled and centred at this point to ensure no one attribute is overly weighted in the cluster analysis.
The following variables have also been removed from the original dataset:
PPG - We will use the PTS_36 (Points per 36 mins) variable to represent scoring volume.
MPG - This has been removed as we want to compare effect when on the court - not how many minutes are being played.
FGA36, FGM_36, FG% -The preference is to split this into the two point and three point equivalents so as not to cloud the differences in shooting types.
Finally, the 3PT% has been restricted to only populate for players with at least 10 threes attempted across all games over the past 4 seasons (otherwise they will get 0 for this variable). This is to remove the ‘flukey’ stats that come about from the few players that end up with very high 3PT% due to only taking a handful of shots in a season.
CREATING THE PLAYER TYPE CLUSTERS
The initial clusters were produced using a fairly standard analysis method; k-means clustering. To calculate the distance between player statistics I have used the standard ‘euclidean’ distance measure.
The following plots help to indicate how many clusters should be used to describe the distinct player types based on the boxscore data. Based on these plots it would appear 12 clusters is the preferred fit. Initially it was thought this might be a little high, but based on how the players fell into the groupings, the results appeared to make sense. There may be some groups that could end up being merged in a future iteration of this work.
[Click image for full size]
VISUALISING THE CLUSTERS AGAINST THE MAJOR INDICATOR VARIABLES
This plot highlights the player type clusters and how the various key indicators relate to how the players have been grouped. For example, you can see how rebounding dominates the first principal component (x-axis) and the usage/scoring stats dominate the second (y-axis).
PLAYER VOLUME BY PLAYER TYPE IDENTIFIED
At this point, the Clusters were re-ordered to help interpretation later in the report (i.e. the groupings are now ordered roughly from the smaller guards, to wings/forwards and finally through to big men). This will become evident further in the post. Here is how the players have been sorted into each of the defined clusters:
CLUSTER 1 - 18 PLAYERS
CLUSTER 2 - 18 PLAYERS
CLUSTER 3 - 11 PLAYERS
CLUSTER 4 - 12 PLAYERS
CLUSTER 5 - 23 PLAYERS
CLUSTER 6 - 12 PLAYERS
CLUSTER 7 - 14 PLAYERS
CLUSTER 8 - 18 PLAYERS
CLUSTER 9 - 7 PLAYERS
CLUSTER 10 - 7 PLAYERS
CLUSTER 11 - 13 PLAYERS
CLUSTER 12 - 12 PLAYERS
PLAYER TYPE CLUSTER HEATMAP
This is a simple heatmap visualising the differences between the key player types identified. Dark blue indicates a high relative ranking across that statistical category, through to white, which indicates the lowest ranking for that category.
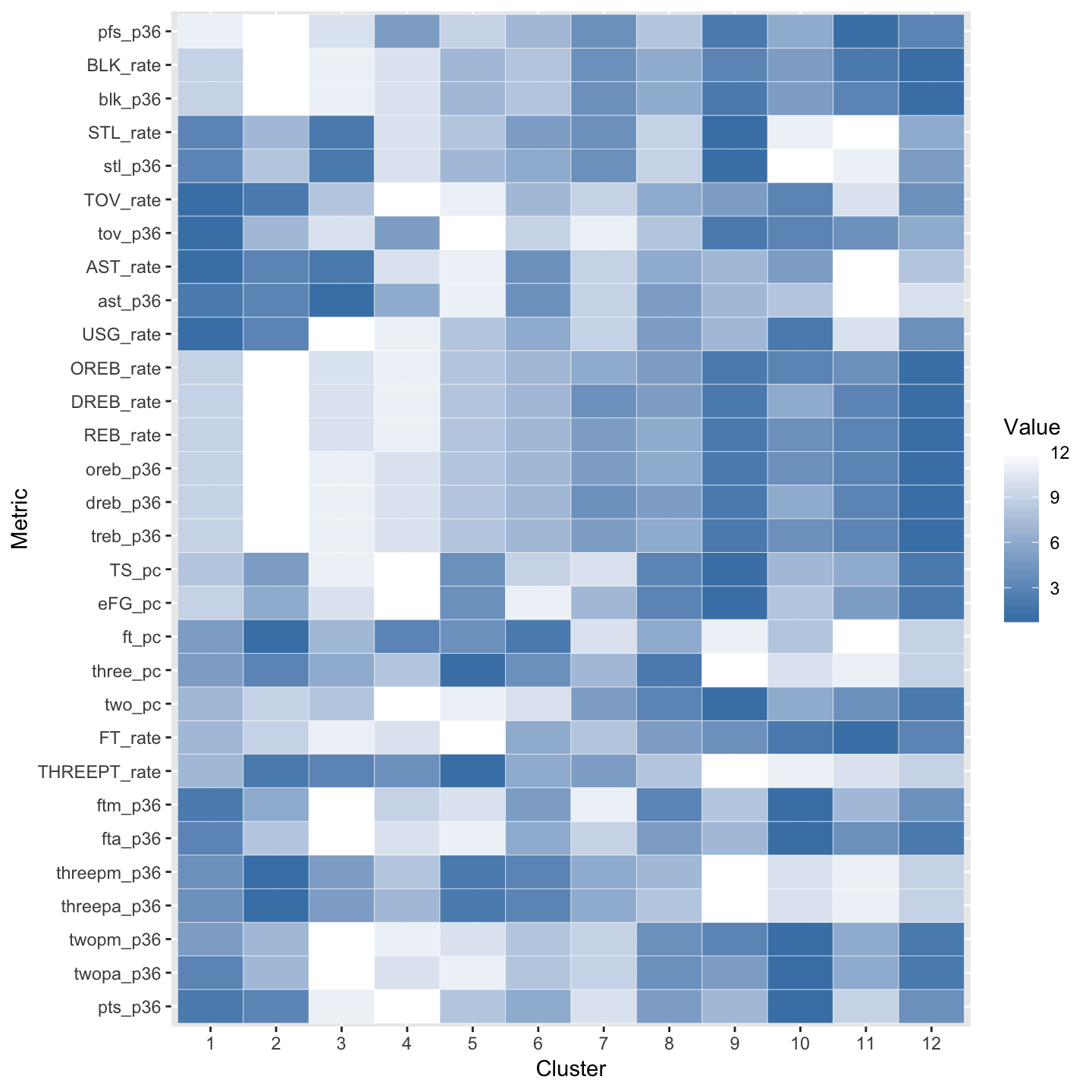
THE CLUSTERS
And here’s the part you’ve been waiting for. Below are the 12 newly created clusters and their associated players from the past 4 NBL seasons (in alphabetical order).
1 | THE BALL DOMINANT STUD

Casey Prather, Cedric Jackson, David Stockton, Dayshon Smith, Demitrius Conger, DJ Newbill, Jean-Pierre Tokoto, Jeremy Kendle, Jerome Randle, Jordair Jett, Lamar Patterson, Marvelle Harris, Melo Trimble, Nathan Sobey, Ramone Moore, Shannon Shorter, Tony Mitchell, Travis Trice
This group has the highest usage rate of all player types and it is dominated by the league’s imports. They take a high volume of shots across all categories (2PT, 3PT and FTs). They also have relatively high assist and turnover stats indicating that the offence will usually run through this type of player and they will often have the ball in their hands. This group also generates a high volume of steals compared to other player types, however don’t rebound the ball at a particularly high rate.
STRENGTHS
Scoring | Get to the free throw line often | Efficient three point shooters | Skilled at creating for others on offence | Good on-ball defenders
WEAKNESSES
Turnover prone | Poor rebounders | Unlikely to offer rim-protection
2 | THE GUNNER

Bryce Cotton, Casper Ware, Chris Goulding, Corey Webster, Daniel Kickert, Ebi Ere, Edgar Sosa, Jarrad Weeks, Jason Cadee, Jermaine Beal, Kevin Lisch, Kirk Penney, Kyle Adnam, Marcus Thornton, Markel Starks, Rotnei Clarke, Stephen Holt, Terrico White
This group shoot the highest volume of 3PT shots (on a per 36min basis) and have the second highest 3 point rate of all player types. They are also accurate with the 2nd best 3PT % and are the most accurate FT shooters. Make sure you close out on these guys! They are also capable of facilitating the offence, ranking 3rd in assists per 36 and AST%. Gunners are the lowest rebounding and blocking group and are only average in the steal based metrics, highlighting their offensive focus.
STRENGTHS
Scoring | Elite three point scorers | Elite Free Throw Shooters | Can create on offence | Unlikely to be in foul trouble
WEAKNESSES
Turnover prone | Very unlikely rebounders | Don’t get to the free throw line often due to reliance on outside shot
3 | THE DEFENSIVE BALL HANDLER

Adam Doyle, Adam Gibson, Damian Martin, Emmett Naar, Indiana Faithfull, Jarrod Kenny, Kevin White, Nate Tomlinson, Peter Hooley, Rhys Carter, Rhys Martin
This player type doesn’t score or rebound the ball well, but does offer a high assist rate while on court and also generates a high volume of steals, indicating more of a defensive focus compared to other ball handlers. When they do take shots at the offensive end, they tend to shoot 3 pointers (shooting at a league average rate).
STRENGTHS
Elite offensive creators | Elite on-ball defenders | Ability to score from range if required | Safe hands on offence
WEAKNESSES
Poor rebounders | Unlikely to shoot free throws | Can’t be counted on as a scoring threat
4 | THE BACK-UP GUARD

Adam Thoseby, AJ Davis, Brendan Teys, Corban Wroe, Dion Prewster, Isaih Tueta, Marshall Nelson, Matt Kenyon, Shane McDonald, Shaun Bruce, Sunday Dech, Terrance Ferguson
This group don’t really dominate any category (as you’d expect for a backup type of role). They do tend to shoot a high proportion of 3 pointers and shoot well from the free throw line. They are about average in terms of assist and turnover rates per 36mins, showing they can take some ball handling responsibilities while on court.
STRENGTHS
Solid free throw shooters | Unlikely to be in foul trouble | Able to create for others in some situations
WEAKNESSES
Do not excel in any particular area | Ineffective scorers | Can’t be counted on as a defensive stopper
5 | THE THREE POINT SPECIALIST

Alex Loughton, Anthony Drmic, Brad Hill, Cameron Gliddon, Clint Steindl, Cody Ellis, Daniel Grida, David Barlow, David Wear, Devon Hall, Dexter Kernich-Drew, Everard Bartlett, Fuquan Edwin, Jordan Ngatai, Mirko Djeric, Oscar Forman, Patrick Richard, Paul Carter, Reuben Te Rangi, Stephen Weigh, Tim Coenraad, Todd Blanchfield, Tom Abercrombie
This group are all 3 point specialists. They dominate in 3 point volume, 3 point rate (ranking 1st), and shooting at a relatively accurate rate compared to other clusters (above average eFG% and TS%). They aren’t typically ‘ball-handlers’, much preferring a catch-and-shoot type role in the offence, as shown by their low assist and turnover rankings. Three Point Specialists are about average in terms of steals and blocking shots compared to other player types and while they can rebound, it’s below what you’d expect for players in this height range.
STRENGTHS
Elite three point shooters | Efficient scorers | Consistent free throw shooters | Ability to stretch the floor | Very unlikely to turn the ball over
WEAKNESSES
Rare free throw shooters | Unlikely passers | Below average rebounders for their size
6 | THE VERSATILE FLOOR SPACER

Brad Newley, Corey Maynard, Damon Heuir, Igor Hadziomerovic, Jack McVeigh, Jaron Johnson, Jesse Wagstaff, Mark Worthington, Mitch McCarron, Mitchell Norton, Shawn Redhage, Shea Ili
This group is interesting as they do a bit of everything, but don’t really excel in any one area. Their scoring is predominantly either shooting threes or getting to the line but they have poor eFG% and TS% compared to other player types (driven by their lower than average 2PT %). They are able to facilitate the offence with an above average AST% and AST/36 ranking. They are in the middle of the pack for most other metrics included in the analysis, indicating that they are capable of contributing across the board when on the court.
STRENGTHS
Great free throw shooters | Ability to score from range | Will look to create for others on offence
WEAKNESSES
Relatively inefficient scorers
7 | THE HIGH-ENERGY 3 & D FORWARD

Armani Moore, Carrick Felix, Craig Moller, Dane Pineau, Greg Hire, Greg Whittington, Jeromie Hill, Jerry Evans Jr, Leon Henry, Lucas Walker, Nnanna Egwu, Owen Odigie, Rhys Vague, Rob Loe
Similar to the Versatile Floor Spacers, this group doesn’t rank particularly high on any individual metric, but they do come in above average in Defensive Rebounding, Steals and Blocks. They’re not the first choice on offence (rank 10th out of 12 in scoring per 36) but when they do look to score, they prefer to shoot 3 pointers (and are reasonably accurate - roughly average compared to all other players).
STRENGTHS
Solid rebounders, particularity on defence | Good defensive players | Ability to stretch the floor on offence
WEAKNESSES
A little foul prone | Poor free throw shooters | Unlikely creators
8 | THE QUALITY FORWARD

Angus Brandt, Anthony Petrie, Brian Bowen, Daniel Johnson, David Andersen, DJ Kennedy, Finn Delany, Harry Froling, Jacob Wiley, Josh Childress, Majok Deng, Mitchell Creek, Nicholas Kay, Perrin Buford, Perry Ellis, Tai Wesley, Tom Garlepp, Torrey Craig
This player type is quality across the board. They don’t rank 1st in any category but are either roughly average or above average in every category except for the two steal based metrics - likely due to them not often guarding ball handlers. They score well relatively well on a per 36mins basis but do so efficiently with high 2PT and 3PT shooting accuracy (and of course TS% and eFG%). The provide quality all-round contributions when they are on the court. These are the glue-guys you want on your team.
STRENGTHS
Solid across the board | Efficient three point threats | Ability to score at the rim | Good rebounders | Offer a little rim protection
WEAKNESSES
Unlikely to be good on-ball defenders
9 | THE DEFENCE-FIRST BIG

Akil Mitchell, Aleks Maric, Derek Cooke Jr, Isaac Humphries, Matthew Burston, Mika Vukona, Ray Turner
This group are very good rebounders and shot blockers and also have a high volume of two point shots, with the highest eFG% and TS% among all player types (indicating they get a lot of dunks and layups). They also give away a high number of personal fouls and generate a lot of steals, highlighting their defensive focus compared to other big man player types. They are the least likely of all the big man groups to look to score.
STRENGTHS
Cannot and will not shoot threes | Great at scoring around the rim | Elite rebounders | Elite Defensive players | Offer rim protection
WEAKNESSES
Cannot and will not shoot threes | Poor free throw shooters | Unlikely to offer a big contribution on offence
10 | THE OFFENcE-FIRST BIG
Brian Conklin, Cameron Bairstow, Cameron Tragardh, Hakim Warrick, Josh Powell, Matt Knight, Nathan Jawai
This group have the characteristics of high-volume scoring big men. I.e. a high % of 2 point shots and go to the FT line at a high rate. They are above average rebounders, but this is more pronounced at the offensive end, highlighting their offensive focus while on the court. This group are ball dominant (rank 2nd in Usage Rate) but aren’t particularly efficient scorers (rank 8th in TS% and 7th eFG%) and tend to turn the ball over at a high rate compared to other player types as well (rank 3rd in TOV%).
STRENGTHS
Cannot and will probably not shoot threes | Elite scorers at the rim | Good rebounders | Will get to the free throw line
WEAKNESSES
Cannot and will probably not shoot threes | Turnover prone | Don’t offer the rim protection of their defensive counterparts
11 | THE TRADITIONAL BIG

Amritpal Singh, Chris Patton, Delvon Johnson, Devin Williams, Eric Jacobsen, Garrett Jackson, Larry Davidson, Luke Schenscher, Majok Majok, Matthew Hodgson, Michael Holyfield, Mitchell Young, Will Magnay
This group doesn’t score at a high rate but are fairly accurate with their two point shots (indicating a high % of shots close to the rim). They get fouled a lot but are poor free throw shooters. They rebound the ball at a high rate when on court and also rank highly in blocked shots and fouls committed, indicating they have a physical presence on the court.
STRENGTHS
Cannot and will not shoot threes | Good rebounders | Offer rim protection | Reasonable scorers around the rim | Good at drawing fouls
WEAKNESSES
Cannot and will not shoot threes | Turnover prone | Foul Prone | Unlikely to be a significant part of the offence | Poor FT shooters
12 | THE HIGH-USAGE BIG

Alex Pledger, Andrew Bogut, Andrew Ogilvy, Charles Jackson, Jameel McKay, Jeremy Tyler, Josh Boone, Julian Khazzouh, Omar Samhan, Rakeem Christmas, Shawn Long, Tom Jervis
This group have an above average usage rate indicating the offense can either run through them, or finish with them. They shoot at a high volume and get to the line with high frequency. Given they are big men, it is no surprise they shoot a high volume of 2 pointers at an accurate rate but are generally poor shooters otherwise (low 3PT and FT %s). They also can be a bit sloppy with the ball with a well above average turnover rate. High-Usage Bigs also dominate the rebounding and blocked shots statistical categories highlighting their all-round value on the court and this appears to be what differentiates them from the Offence-First Bigs group who aren’t typically as well rounded as these guys.
STRENGTHS
Elite rebounders at both ends of the court | Get to the line often | Great around the rim | Elite shot blockers
WEAKNESSES
Unlikely to create for others | Unlikely to be a three point threat | Generally poor free throw shooters
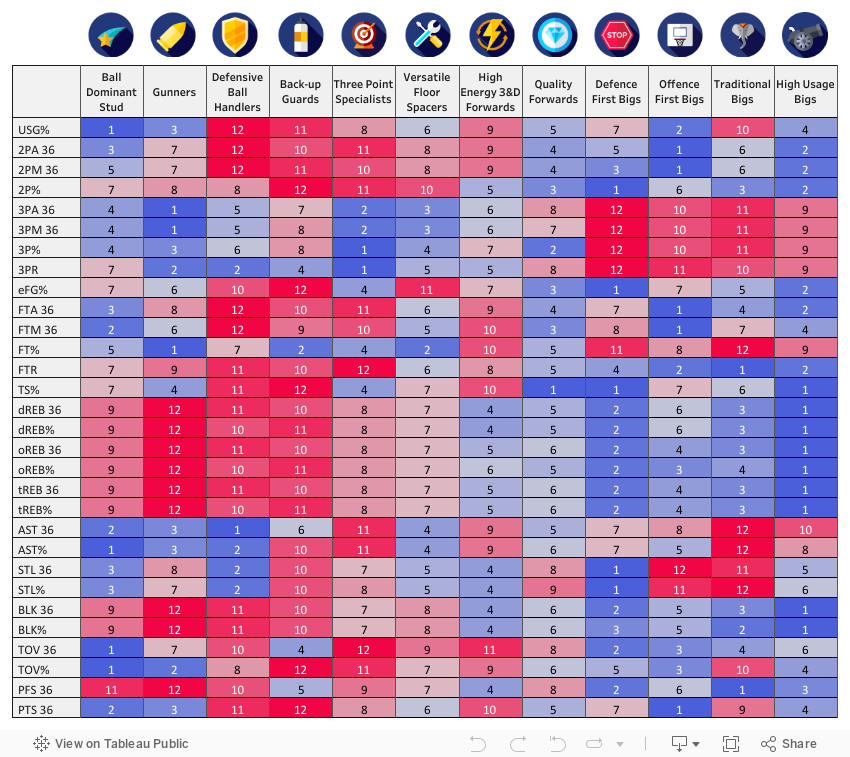
CLUSTER RANKINGS BY METRIC
A summary of how the players in each group relate to the wider group of players and the other clusters is summarised in the table below. The lower the ranking, the better a particular cluster performs in the given statistical area.
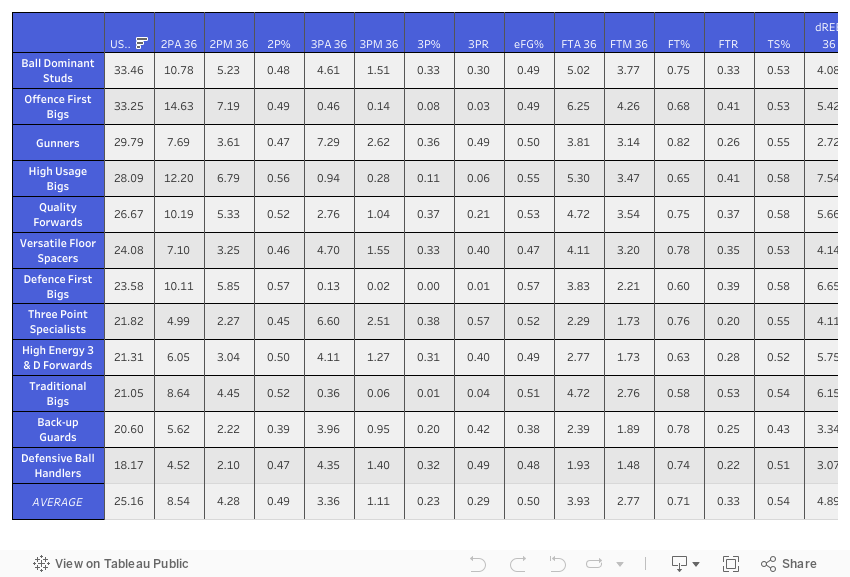
AVERAGE STATS BY PLAYER TYPE/CLUSTER
A simple table summary showing the average statistics across each category for each cluster.
CREDITS AND REFERENCES
This work has been inspired by some very useful and informative posts relating to work looking at classifying players based on their boxscore stats in the NBA. In particular, I need to acknowledge the authors of these two particularly useful posts that helped with some ideas about how to conduct this analysis.
https://fastbreakdata.com/classifying-the-modern-nba-player-with-machine-learning-539da03bb824
Of course, this work wouldn’t be possible without Andrew pulling together such a great dataset and allowing me to work with it (and providing much expert advice along the way).
By no means is this a finished product and would welcome any feedback on how to improve this work. We have some ideas about how to take this and turn it into actionable insight around optimal lineups using these player type groupings, so this will be coming in due course.